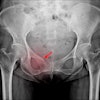
Multimodal large language models (LLMs) have improved in the past year in answering RSNA Case of the Day questions, with the best performing model on par with expert radiologists, according to research published August 12 in Radiology.
The findings are an extension of a study published last year and emphasize the growing potential of multimodal LLMs in radiologic applications, noted lead author Benjamin Hou, PhD, of the National Institutes of Health in Bethesda, MD, and colleagues.
“With GPT-o3 and GPT-5 on the horizon, further advancements and enhancements in model capabilities are anticipated, and it will be intriguing to see how the models perform,” the group wrote.
Since the release of GPT-4V (GPT-4 with vision capabilities) in September 2023, a number of multimodal LLMs capable of processing both text and image inputs have emerged. As an extension of research the group conducted last year, in this study, they investigated whether LLMs have advanced in interpreting radiologic quiz cases.
The researchers used 95 Case of the Day questions from RSNA 2024 and 76 questions from the 2023 meeting as a baseline for comparison. The LLMs included OpenAI o1 (OpenAI), GPT-4o, GPT-4, Gemini 1.5 Pro (Google), Gemini 1.5 Flash (Google), Llama 3.2 90B Vision (Meta), and Llama 3.2 11B Vision (Meta). The models were evaluated and compared with each other and with the accuracy of two senior radiologists.
According to the analysis, the models have significantly improved over the past year, with OpenAI’s latest models outperforming those from Google and Meta; notably, OpenAI o1 had an accuracy comparable to expert radiologists, the researchers noted.
Key results included the following:
The accuracy of OpenAI o1 (59%; 56 of 95) surpassed Google’s Gemini 1.5 Pro (36%; 34 of 95) and Meta’s Llama 3.2-90B-Vision (33%; 31 of 95).
OpenAI o1 demonstrated higher accuracy than OpenAI’s GPT-4 on questions from 2024 (59% [56 of 95] vs. 41% [39 of 95], p = 0.03) and on questions from 2023 (62% [47 of 76] vs. 43% [33 of 76], p = 0.09).
The accuracy of OpenAI o1 on the questions from 2024 (59%) was comparable to two senior radiologists who scored 58% (55 of 95; p = 0.99) and 66% (63 of 95; p = 0.99) on the same questions.
“Our study highlights the substantial advancements in multimodal large language models (LLMs) during the past year,” the group wrote.
Future research should aim to standardize evaluation frameworks, develop datasets with detailed annotations, and explore the integration of these models into real-world clinical workflows to assess their impact on diagnostic accuracy and efficiency, the group wrote.
In an accompanying editorial, Chong Hyun Suh, MD, PhD, of the University of Ulsan, and Pae Sun Suh, MD, of Yonsei University, wrote that the study presents a comprehensive evaluation of how multimodal LLMs have advanced over the past year, and noted that even at this moment, such models are improving in their vision capabilities.
“While several issues remain to be explored, it is clear that radiologists can anticipate further enhancements of multimodal capability and should prepare for potential integration of these tools into various areas of radiology practice,” Suh and Suh concluded.
The full study is available here.